在微服务架构中,日志管理是一个重要的环节。为了有效地收集和处理日志,常常会用到 ELK(Elasticsearch、Logstash 和 Kibana)堆栈。然而,Logstash 并不是唯一的日志收集器,尤其是我的服务器配置极低,想要运行Logstash会给服务器带来更大的压力。Filebeat 作为轻量级的日志收集器,常常用于将日志直接发送到 Elasticsearch。本文将介绍如何在 Kubernetes 环境中,使用 Filebeat 作为 sidecar 容器来采集应用容器的日志,并将其发送到 Elasticsearch 进行集中处理。
前提条件
在开始之前,请确保你的 Kubernetes 集群已经搭建完毕,并且可以正常使用 kubectl 命令与集群交互。此外,你还需要一个可用的 Elasticsearch 实例来接收 Filebeat 发送的日志数据。本文默认日志文件中每行都是JSON格式
部署 Elasticsearch
首先,我们需要在 Kubernetes 中部署 Elasticsearch,并将其限制在特定的资源范围内。以下是一个简单的 Elasticsearch 部署配置文件:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:8.5.0
resources:
limits:
memory: "1Gi"
cpu: "500m"
requests:
memory: "512Mi"
cpu: "500m"
env:
- name: ES_JAVA_OPTS
value: "-Xmx512m -Xms512m"
ports:
- containerPort: 9200
- containerPort: 9300
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: default
spec:
type: NodePort
selector:
app: elasticsearch
ports:
- port: 9200
targetPort: 9200
nodePort: 30001 # Node节点的端口,<>nodeIP>:nodePort 是提供给集群外部客户访问service的入口
---
apiVersion: v1
kind: ConfigMap
metadata:
name: elasticsearch
namespace: default
data:
es-config: |-
cluster.name: "docker-cluster"
network.host: 0.0.0.0
node.name: "es1"
cluster.initial_master_nodes: "es1"
xpack.security.enabled: false
http.cors.enabled: true
http.cors.allow-origin: "*"
http.host: 0.0.0.0
部署Kibana
我们需要在 Kubernetes 中部署Kibana来查看投递到Elasticsearch的日志。以下是一个示例配置文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:8.5.0
env:
- name: ELASTICSEARCH_URL
value: "http://elasticsearch.default.svc.cluster.local:9200"
ports:
- containerPort: 5601
resources:
limits:
cpu: "100m"
requests:
cpu: "100m"
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: default
spec:
type: NodePort
selector:
app: kibana
ports:
- port: 5601
targetPort: 5601
nodePort: 30002当所有服务配置好后可通过Nginx反向代理到NodeIP:30002来访问Kibana。
以下是一个简单的配置:
server {
listen 80;
server_name youdomain.com;
location / {
proxy_pass http://172.22.0.1:30002/;
}
}
部署应用和 Filebeat
接下来,我们需要部署应用容器,并在同一 Pod 内添加一个 Filebeat sidecar 容器来收集日志。以下是一个示例配置文件:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: gateway
namespace: default # 声明工作空间,默认为default
spec:
replicas: 1
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
name: gateway
template:
metadata:
labels:
name: gateway
spec:
containers:
- name: gateway-container
image: wrathzou/gateway:latest
imagePullPolicy: Always # 始终尝试重新拉取容器镜像,即使节点上已经存在相同标签的镜像
ports:
- containerPort: 8000 # containerPort是声明容器内部的port
volumeMounts:
- name: log-volume
mountPath: /app/log/wrath.blog.cc # 将日志文件挂载到容器内的路径
- name: filebeat
image: docker.elastic.co/beats/filebeat:8.5.0
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 0 # 以 root 用户运行
volumeMounts:
- name: log-volume
mountPath: /app/log/wrath.blog.cc
- name: filebeat-config
mountPath: /usr/share/filebeat/filebeat.yml
subPath: filebeat.yml
volumes:
- name: log-volume
emptyDir: {} # 使用 emptyDir 来共享日志文件
- name: filebeat-config
configMap:
name: filebeat-config # 引用 ConfigMap 来提供 Filebeat 配置
---
apiVersion: v1
kind: Service
metadata:
name: gateway-service
namespace: default # 声明工作空间,默认为default
spec:
type: NodePort
ports:
- name: http
port: 18000
targetPort: 8000
nodePort: 30000
selector:
name: gateway
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: default
data:
filebeat.yml: |-
filebeat.inputs:
- type: filestream
enabled: true
id: gateway-filestream-id
paths:
- /app/log/wrath.blog.cc/*.log
fields:
topic: gateway
# 定义模板的相关信息
setup.template.enabled: true
setup.template.name: "blog"
setup.template.pattern: "blog-*"
setup.template.overwrite: false
setup.ilm.enabled: false
output.elasticsearch:
hosts: ["elasticsearch.default.svc.cluster.local:9200"]
pipeline: "parse-message" # 用于洗数据,文章末尾会介绍
index: "blog-%{[fields.topic]}-%{+yyyy.MM.dd}"
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
- timestamp:
# 格式化时间值
field: create_time
layouts:
- '2006-01-02 15:04:05'
- '2006-01-02 15:04:05.999'
test:
- '2019-06-22 16:33:51'
- drop_fields:
fields: ["@timestamp","@version","agent.name","event.original","@event.original","input_type", "log.offset", "host.name", "input.type", "agent.hostname", "agent.type", "ecs.version", "agent.ephemeral_id", "agent.id", "agent.version", "fields.ics", "log.file.path", "log.flags" ]
setup.dashboards.enabled: false配置内核参数
在部署 Elasticsearch 前,需要确保宿主机的内核参数 vm.max_map_count 设置正确。这个参数影响了进程能映射的最大内存区域数量,Elasticsearch 需要将其设置为至少 262144:
sudo sysctl -w vm.max_map_count=262144验证部署
完成部署后,可以使用以下命令检查 Elasticsearch 是否运行正常:
kubectl get pods
kubectl logs <elasticsearch-pod-name>检查 Filebeat 是否正常读取日志并发送至 Elasticsearch:
kubectl logs <gateway-pod-name> -c filebeat格式化日志
进入Kibana后,由于我们的ELK架构中缺少了Logstash洗数据,所以我们的日志内容全部处于message字段中,所以此时需要创建一个 Ingest Pipeline,用于解析 fields.message 中的 JSON 数据,这个 Pipeline 会自动解析 JSON 并将其字段化。
使用 Kibana Dev Tools 来创建这个 Pipeline:
PUT _ingest/pipeline/parse-message
{
"description": "Parse message field as JSON",
"processors": [
{
"json": {
"field": "message",
"add_to_root": true,
"ignore_failure": true
}
}
]
}创建索引生命周期
为了防止索引文件随着时间增长而占用过多的磁盘,我们需要设置一个合适的索引生命周期。

我们进入上图的页面创建一个策略。输入策略名称后,点击删除icon

随后页面会出现下图的配置项,输入过期时间即可
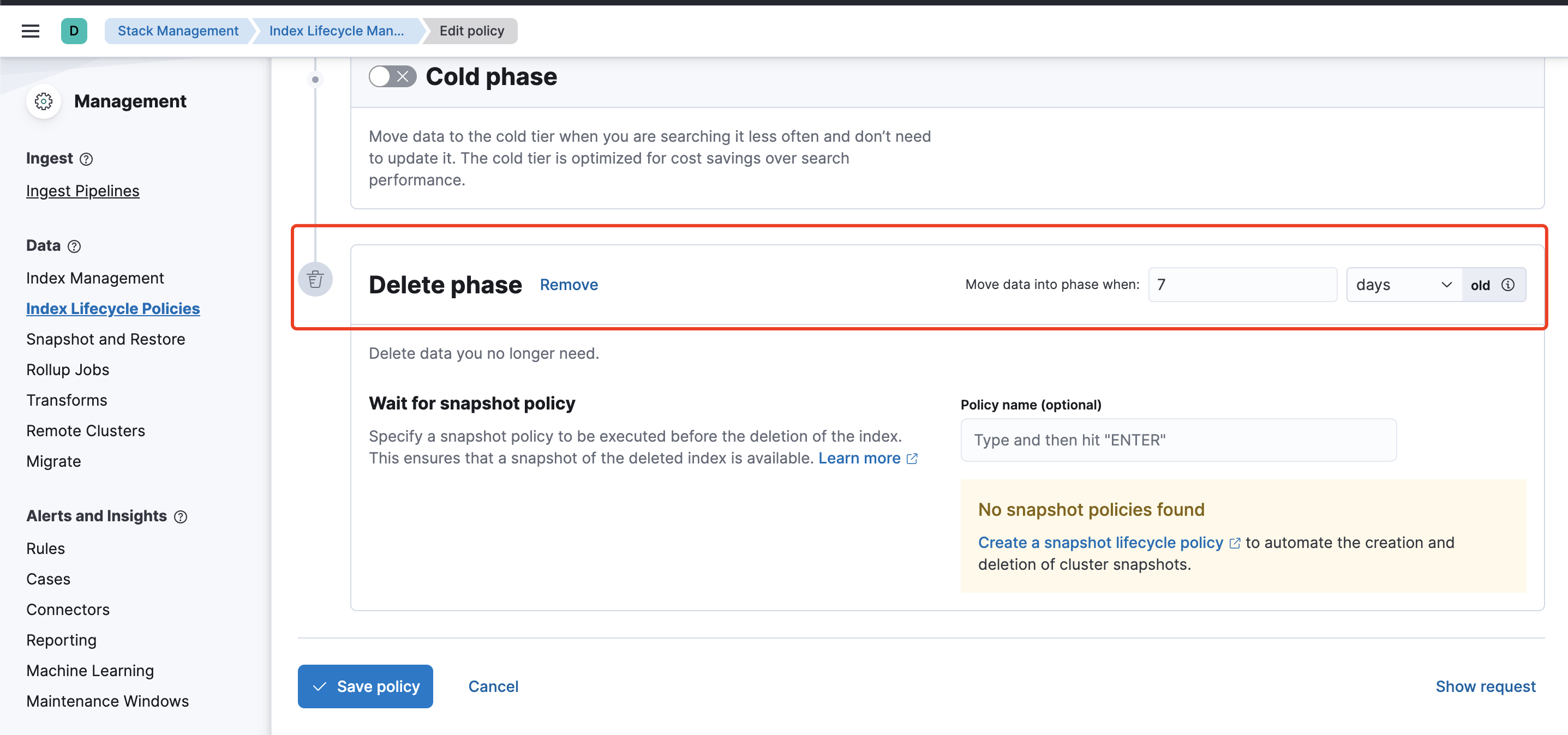
保存后回到外面的列表,点击你刚刚创建的策略右边的“+”icon

输入此策略匹配的索引模板后保存即可
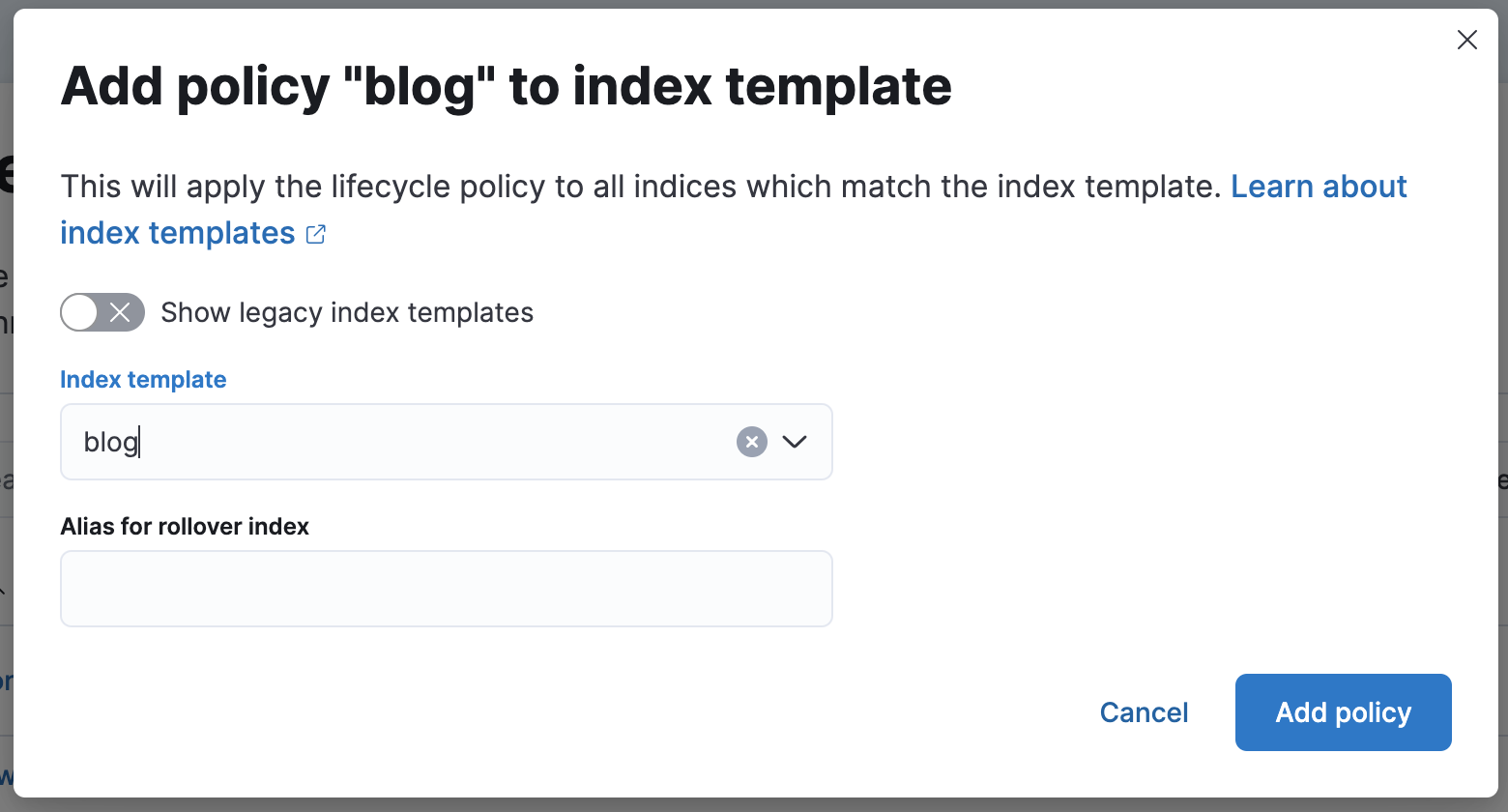
如果索引模板名称正确则列表会出现匹配的数量

参考文献:
Comments